10XCrew
Building a webscraper in Python to scrape data from Amazon and analyse this data for the 10XCrew team.
GitHub repository
Coding a Python scraper
My goal for this project was to be responsible for building a web scraper in Python that could be used throughout the project to gather necessary data. The source code for this scraper can be found on GitHub .
This scraper has one purpose: request a number of products from an Amazon search query page and export all the data for each product (pdp position, url, canonical url, name) to an Excel sheet. This exported data could then be imported into Ahrefs to analyze the backlinks for each canonical url. Unfortunately, the 10XCrew team didn't give us an enterprise level account, which would've given me access to the Ahrefs API and the ability to directly access backlink data through my Python scraper.
Since I didn't have any experience with Python before this project, I asked my good friend ChatGPT for some direction on how to build something like this. I quickly realized there were some very useful Python packages like pandas, requests and BeautifulSoup that can be used to gather and format data.
Bypassing issues
While the initial coding process went well, I found out Amazon doesn't like when people scrape their pages due to server loads. I had to find a way to bypass this problem, which I did by providing headers and a user agent to my requests. I also had to find a way to bypass the CAPTCHA Amazon throws at my scraper. I bypassed this by making sure the query link I used was a public link available everywhere, and rate-limiting my requests by using the time.sleep() method in Python.
Results
Once I got past the Amazon protections, I started printing the response I got from my scrape request to see if it gathered the right products:
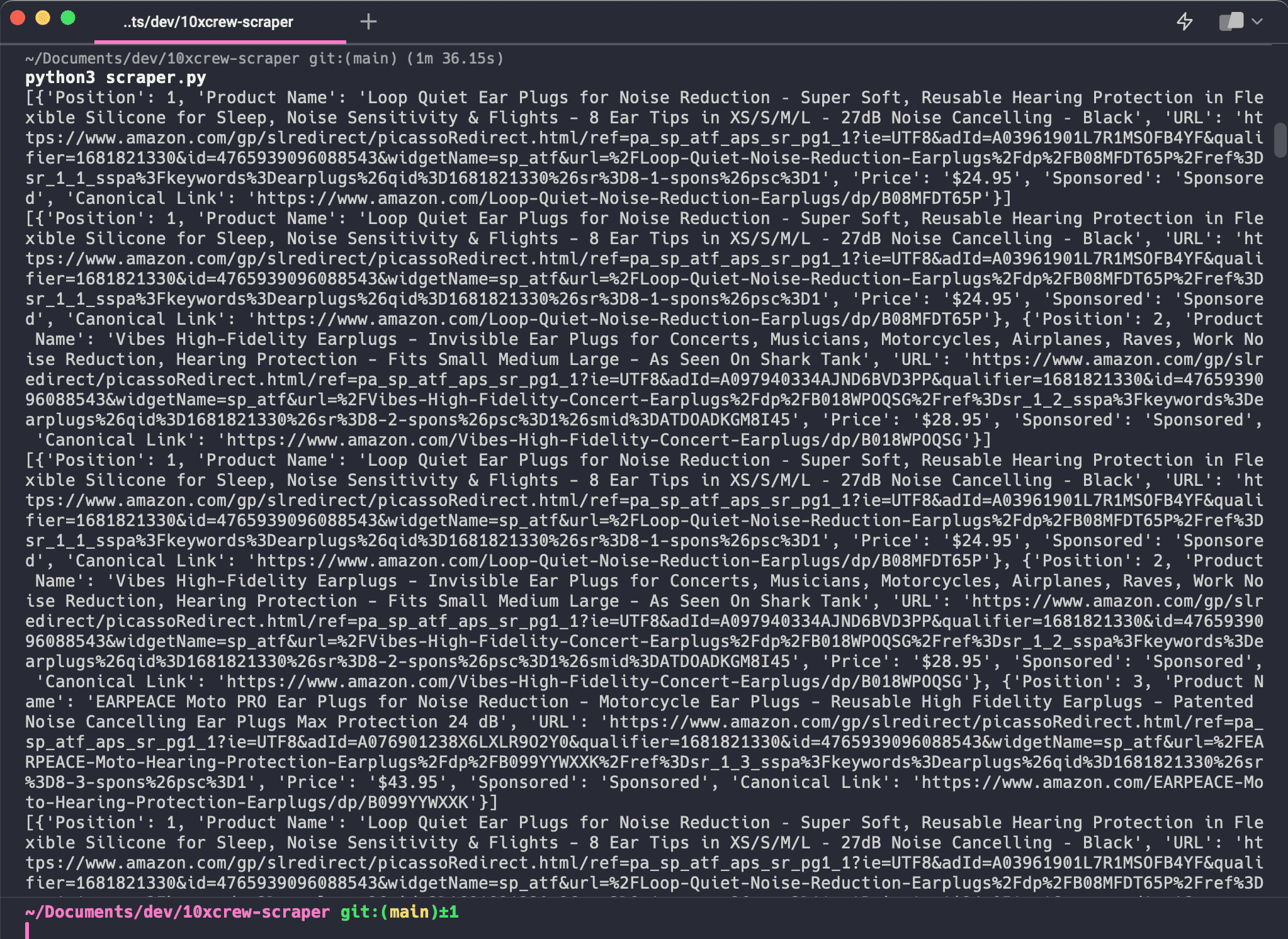
10XCrew - Python Scraper - Printed response
With this data, I added extra features and filters such as checking if an item is sponsored or organic, which I then exported to an .xlsx file using the pandas library. This produced a nice and organized sheet of products:
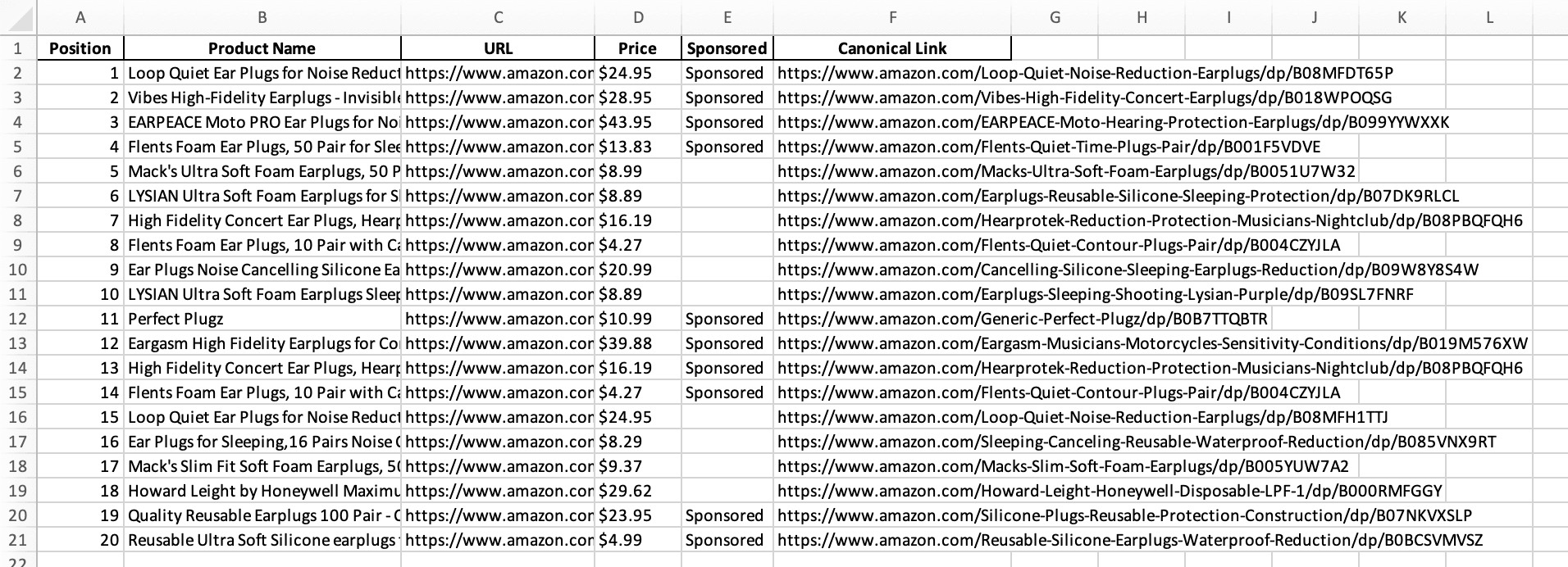
10XCrew - Python Scraper - Exported data
Improvements
While this version of the script worked as it exported the data I wanted, it was very slow because it was making new requests to Amazon for every result, to get the correct canonical link after the result had already been loaded.
To optimize this, I asked guest teacher Klaas Cox for advice and he showed me that instead of making a new request, I could use Regex to chop the product url in pieces and glue the pieces from the url I needed back together, to create my own canonical link without having to ask Amazon for a second time. The changes I made to fix this can be seen in this commit on GitHub
After some fine tuning, I was able to fix all bugs such as canonical links not being appended and ended up with working scraper that could gather 100 results from Amazon in under a second, a massive improvement over the earlier version which took nearly 3 minutes for 50 results.

10XCrew - Python Scraper - Bug Fixes
What went well?
Coding the webscraper went really smooth and it was surprisingly simple. Although I had some issues bypassing Amazon's scraping security I was able to solve them fairly quickly and efficiently.
I expected to need more time and effort in building this webscraper as I built it by myself with no prior Python experience, but asking ChatGPT for suggestions about libraries really sped up my process. Fine tuning it took some time, but I'm very happy with the end result.
What could've gone better?
Unfortunately, I was only able to code the scraper for Amazon search queries. I would've liked to implement the Ahrefs API to help my project group out with more useful data, however this required paid access that I wasn't able to get during this project.
What did I learn?
Building this web scraper was the first real project I built using Python, therefore I gained a lot of practical experience using Python and modern libraries. I learnt how to make requests and print out data from a response, as well as how I can format this data and export it and use Regex to filter results. I also learned how to troubleshoot Python apps by using ChatGPT as a coding assistant.